Key Takeaways
- A 2025 study found that AI systems prefer CVs rewritten by themselves over equivalent human-written versions — by 67% to 82%
- The bias stems from stylistic self-recognition, not content quality differences
- In simulated hiring pipelines, AI-polished candidates were 23–60% more likely to be shortlisted
- The risk is real but avoidable — it depends entirely on how the AI is used in the screening process
- Systems that anchor evaluation to specific job requirements, extract structured facts, and score deterministically are largely immune to this effect
In September 2025, researchers from the University of Maryland, the National University of Singapore, and Ohio State University published a paper titled “AI Self-preferencing in Algorithmic Hiring: Empirical Evidence and Insights” (Xu, Li & Jiang, 2025). The findings are striking — and worth understanding carefully if you use AI in any part of your hiring process.
This post breaks down what the study actually tested, what it found, what it means for employers, and how hiring systems can be designed to avoid this specific type of bias.
What the Researchers Tested
The study used 2,245 real human-written CVs across 24 occupational categories. For each CV, nine different AI models (including GPT-4o, DeepSeek-V3, and LLaMA 3.3-70B) were asked to rewrite the executive summary section — the short professional profile at the top of the CV.
The rest of the CV was left identical. This is the key design choice: the candidate’s experience, skills, education, and work history were exactly the same. Only the way the summary was written changed.
The researchers then asked the same AI models to act as resume screeners. Each model was shown two versions of a CV and asked: “Which candidate’s resume is stronger?”
Critically, the evaluator received no job description, no competency framework, and no matching criteria. It made a subjective judgment based on overall impression.
What They Found
The results were consistent across nearly all models:
- LLM-vs-Human: 8 of 9 AI models preferred their own rewritten summaries over the original human-written ones, with raw preference rates ranging from 26% to 98%. After controlling for content quality using conditional logistic regression, the bias remained at 67–82% for larger models including GPT-4o, DeepSeek-V3, and LLaMA 3.3-70B.
- LLM-vs-LLM: When an AI compared its own rewrite against another AI’s rewrite of the same CV, the results were more mixed — but DeepSeek-V3 in particular showed strong self-preference.
- In simulated hiring: Across 24 occupations, AI-polished candidates were 23–60% more likely to be shortlisted. The effect was strongest in business-related roles like sales and accounting.
- Even when humans disagreed: In cases where human annotators judged the original human-written summary to be better, the AI evaluator still preferred its own version.
Why This Happens
The researchers link this to self-recognition — larger AI models appear to recognize stylistic patterns from their own outputs and rate them more favorably. This is not a content quality judgment. It is a stylistic preference, closer to recognizing one’s own handwriting than to evaluating someone’s qualifications.
The paper cites supporting research showing that AI models can reliably distinguish their own text from alternatives (Panickssery et al., NeurIPS 2024), and that this recognition capability correlates with stronger self-preference.
What This Means for Employers
If your hiring process uses AI to make subjective quality judgments about CV text — “which candidate sounds better?” — you are potentially exposed to this bias. The practical consequences are significant:
- Candidates who use the “right” AI tool gain an unfair advantage. If your screening AI is GPT-4o and a candidate used GPT-4o to polish their CV, they get a built-in boost — regardless of whether they are actually more qualified.
- Socioeconomic disparities get amplified. Access to premium AI tools is not evenly distributed. If hiring outcomes depend on which AI a candidate used, the system disadvantages those who cannot afford — or choose not to use — these tools.
- Repeat cycles create lock-in. Over time, if AI-polished CVs consistently outperform human-written ones, more candidates will use AI, and the stylistic norms of the dominant AI model become entrenched in the applicant pool.
How to Avoid This Bias: Design Principles
The good news: this bias is architectural, not inevitable. It depends on how the AI is used, not whether it is used. The researchers themselves found that simple interventions — system prompt modifications and ensemble voting — can reduce bias by over 50%.
But the more fundamental mitigation is structural. Based on the study’s findings, here are the design principles that eliminate or dramatically reduce the risk:
1. Never Compare CVs Against Each Other
The study’s core methodology is pairwise comparison: “CV A vs. CV B — which is better?” This is where self-preference bias thrives. If your system evaluates each candidate individually against defined job requirements, this comparison dynamic never occurs.
2. Anchor Evaluation to Specific Job Requirements
The evaluator AI in the study received no job description. It made a generic “which sounds stronger?” judgment. When AI is given concrete competencies with defined importance weights and required expertise levels, the evaluation is anchored to objective criteria rather than stylistic impression.
3. Extract Facts, Don’t Judge Quality
The self-preference bias is fundamentally about writing quality. If the AI’s role is to extract structured information — identifying what skills are present, classifying proficiency levels based on explicit evidence — the writing style of the CV becomes much less relevant. Whether a CV was polished by AI or written plainly, the extractable facts remain the same.
4. Score Deterministically
If the AI extracts categorical proficiency levels (beginner, intermediate, senior, expert) and a separate, non-AI scoring engine computes the numeric score using weighted formulas, the final output is insulated from any stylistic bias in the AI’s processing. The AI classifies; the algorithm scores.
5. Require Evidence
When the AI is required to provide exact quotes from the CV to support each classification, hallucinated or inferred evidence can be caught. This creates an audit trail and further constrains the AI to factual extraction rather than subjective assessment.
6. Keep Humans in the Loop
AI should produce recommendations with full transparency — showing calculation traces, supporting evidence, and skill-by-skill breakdowns. The recruiter makes the final decision, informed by structured data rather than a single AI-generated label.
How Omniteam Approaches This
At Omniteam, we designed our CV evaluation system specifically to avoid the class of bias this research identifies.
Our system evaluates CVs based on job-related technical competencies. We deliberately do not assess behavioral competencies from CVs, as these cannot be reliably extracted from written text alone — that assessment happens during the structured interview phase.
We evaluate candidates in two ways:
Talent Pool Filtering uses a fully deterministic, algorithmic matching engine. It compares structured candidate data — extracted skills, years of experience, certifications, domain exposure — against the job’s technical competencies using rule-based scoring. No AI language model is involved in this scoring at all.
Individual CV Analysis uses AI (via Azure OpenAI) for a specific, bounded task: reading the CV text and classifying the candidate’s proficiency level for each required technical skill based on explicit evidence found in the CV. The AI operates with fixed parameters for reproducible outputs, must provide supporting quotes from the CV text, and outputs structured categorical data — not subjective assessments. The final numeric score is then calculated by a deterministic scoring engine using weighted averages of these classifications.
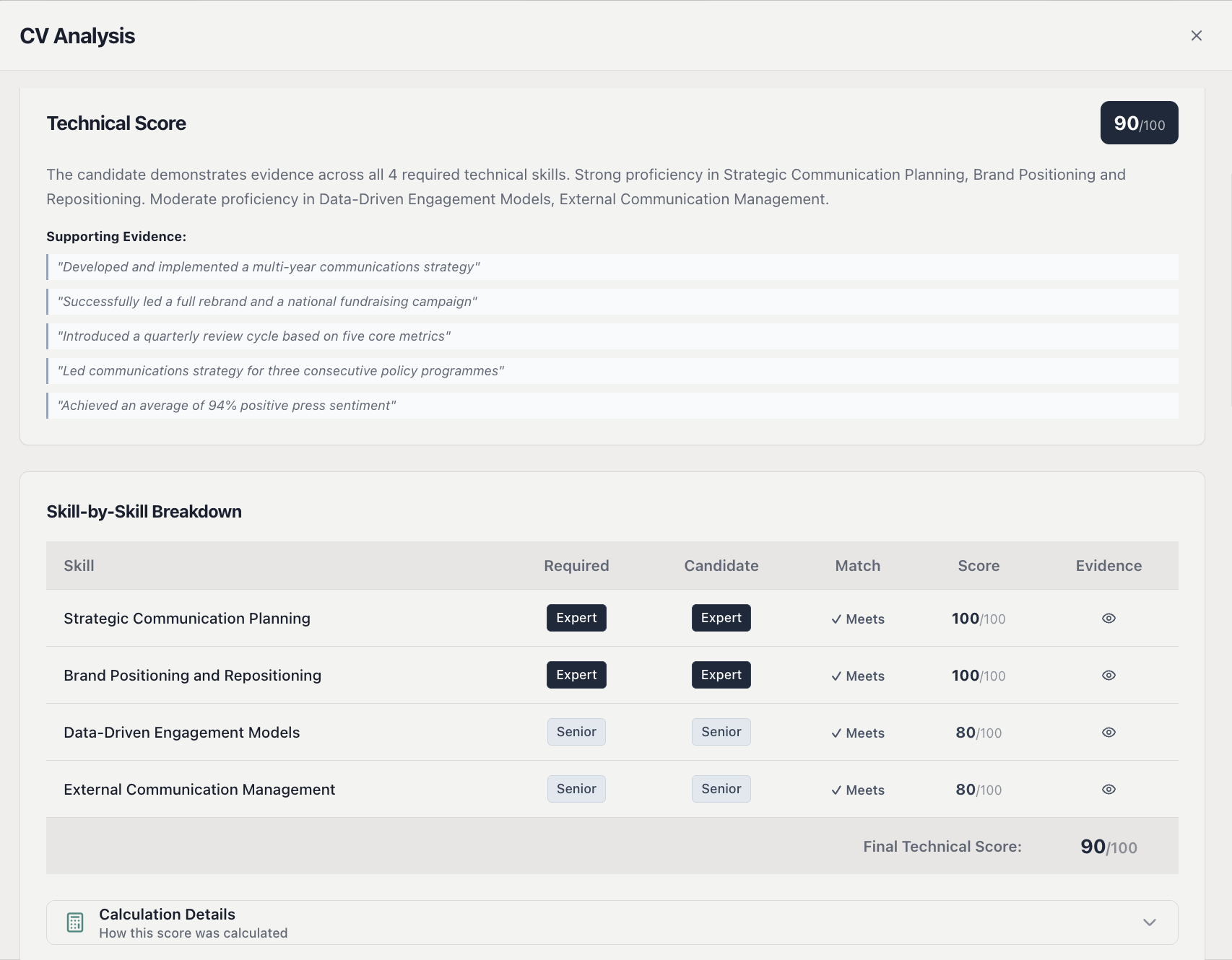
Every AI output passes through automated bias detection for protected characteristics, EU AI Act compliance validation, and quote verification against the original CV text. If bias is detected, the analysis is rejected entirely.
The result is a system where the AI never compares candidates against each other, evaluation is always anchored to specific weighted job competencies, the AI extracts structured facts while a separate algorithm computes scores, every score has a full calculation trace and evidence trail, and the recruiter always makes the final decision with complete transparency.
The Broader Takeaway
The Xu, Li & Jiang study is an important contribution to understanding AI bias in hiring. But the takeaway is not “don’t use AI in screening.” It’s “design your AI system so that stylistic preferences cannot influence outcomes.”
The bias the researchers found is specific to a pattern: an AI making unconstrained subjective judgments about text quality. When AI is used as a structured extraction and classification tool — anchored to specific job requirements, validated against evidence, and scored deterministically — the conditions for self-preference bias are fundamentally removed.
As AI becomes more prevalent in both CV writing and CV screening, the architecture of hiring systems matters more than ever. The question isn’t whether to use AI — it’s whether the AI’s role is designed to produce fair, reproducible, and evidence-based outcomes.
References
- Xu, W., Li, G., & Jiang, J. (2025). AI Self-preferencing in Algorithmic Hiring: Empirical Evidence and Insights. arXiv:2509.00462. Link
- Panickssery, A., Bowman, S.R., & Feng, S. (2024). LLM Evaluators Recognize and Favor Their Own Generations. NeurIPS 2024. Link
- Laurito, W. et al. (2025). AI–AI Bias: Large Language Models Favor Communications Generated by Large Language Models. PNAS 122(31). Link
- EU AI Act, Regulation (EU) 2024/1689. Link